发布时间:2019-09-24 18:00:49编辑:文明阅读(1522)
看到《阿里巴巴java编码规范》有这样一条

关于这条规范,我说说我个人的看法
用不用存储过程要视所使用的数据库和业务场景而定的,不能因为阿里巴巴的技术牛逼,就视他们的手册里的每一项规范为圣经, 盲目的去遵循。
对于手册中的这项规范,我觉得使用MySQL的程序员认同占多数, 而使用SQL Server的程序员反对占多数。 原因在于MySQL对SQL编程和复杂查询性能优化的支持实在太烂。不过从手册的上下文来判断这条规范应该就是针对MySQL的。

记得MySQL支持存储过程是5.0版本开始的, 那时候已经是2006年了,而从新版本发布到用户全面升级,势必要延迟几年, 而同时期的Sql Server2005和Sql Server2008的Transact-SQL编程已经相当成熟,不是MySQL能够追赶的上的。 而业务逻辑这个东西,可以放在SQL端实现也可以放在语言端实现,恰恰MySQL对于SQL编程支持的不完善,造成使用MySql数据库的程序员都偏向于把逻辑放在语言中实现,加上互联网的蓬勃发展,MySQL使用场景越来越广,此消彼长, SQL编程技术也就越来越不招人待见。
然而,这并不能表明SQL编程无可取之处。
在微软技术栈程序员中,存储过程绝对神器级的解决问题手段,不管是存储过程, 视图、触发器、自定义函数这些都是极常用的技术。而这些在MySQL中基本上是见不到的,在开发基于MySQL的项目中,要是有人胆敢使用此类技术,绝对会被视为异端, 并毫不留情的遭受打压。在微软技术栈中,优先推荐将业务逻辑使用Transact-SQL编程实现,封装在数据库中, 供外部.Net程序调用。有的项目通过这种方式实现,外部的程序就是个空壳子,所有复杂的逻辑全在数据库里面。 拿MVC模式打比方,model层的内容全在数据库里, 程序中只剩Controller和View层的内容, 这会让人产生一种编程语言没鸟用的错觉。 但是这样做是有好处的。
首先,很多人说存储过程性能不行,其实也不一定, 尤其是Sql Server。大规模高并发分布式场景下SQL编程不占优势,但是并非所有应用都是如此的, 在普通应用场景下,SQL编程的性能优势就体现出来了。 因为编程语言对数据库的操作最终都会转化为SQL语句传递给数据库执行, 那在具备优秀的SQL编程能力的情况下,通过SQL编程实现业务逻辑显然比通过程序语言实现更底层, 粒度更细, 和数据库本身结合的更紧密,更利于性能调优。 虽然原本在程序端的计算量被转移至了数据库端, 程序端压力小, 数据库端压力大, 但是两者相加的总压力却变小了,因为把逻辑放在程序端实现,无法百发百的压榨数据库性能,从而导致资源浪费。 通过SQL编程实现业务逻辑, 数据库压力虽然大了,却可把原来属于程序端的服务器资源划给数据库端,这样在总体上来说资源不但不浪费,而且还节省了。 通过数据库实现业务逻辑的性价比更高。再者,大多数程序的业务逻辑无非是对数据库的增删查改,没有谁比SQL更适合干这个事情,包括编程语言,因此用SQL编程来实现业务逻辑最合适不过。 不要说什么SQL编程不支持面向对象,无法解决复杂问题,先不说大多数项目没有到达复杂的程度, 现在主流的ORM框架的实现都是不符合理论的,谁说关系表可以映射为对象的,荒唐。况且,SQL语句面向结果编程符合的函数式编程模式,而函数式编程是现代编程界的一股清流,牛逼之处不言而喻。 即使真碰到什么问题是SQL编程无法解决的,也可以把这部分问题提取出来通过程序实现, 但我相信这样的问题总是占少数的。
其次, 把逻辑封装在存储过程里,有一个好处是改动方便。 改程序需要重新编译、停服、发布, 存储过程是可以热更新的, 能减小发布程序所带来的影响。在以SQL Server为基础的程序中,光上面说的这些也足够成为用SQL编程实现业务逻辑的理由了。但在MySQL下是不成立的, 我曾经见过一个.net程序员强行把MySQL当SQL Server使,结果项目后期维护跟翔一样臭。
这个Java手册是从阿里巴巴的业务场景中提炼出来的, 照着它练能做出很厉害的项目来。但是在整个软件开发行业,不是所有的企业都是互联网公司, 即使在整个互联网行业中,也不是所有的公司都是阿里巴巴,不是所有的项目都要应对巨量请求,不是所有的项目都使用MySQL数据库。 诚然, 这个手册的规则是正确无疑的,可就像韦小宝说的,跟小皇帝打架用的着花几十年时间练化骨绵掌吗,花几小时练挤奶龙爪手就足够了。 所以, 是不是用存储过程还是视实际情况而定,一票否决是不明智的。
还有,那些说存储过程难以调式难以修改的, 要不就是没用对数据库, 要不就是SQL编程能力不足。以我个人的经验来说,存储过程是个好东西,尤其在SQL Server下。如果数据库仅仅是用来当存储数据的仓库,那像Oracle、IBM、Microsoft用的着费劲把它们产品的功能做这么强大吗, 那些已故的数库领域的先驱都要死不瞑目了。
--
公司有一套Web系统, 使用方反馈系统某些页面访问速度缓慢, 用户体验很差, 并且偶尔还会出现HTTP 502错误。
这是典型的服务器端IO阻塞引发的问题,通过对访问页面的程序逻辑进行跟踪,发现问题应该是出在某个SQL查询上。
在页面程序运行的某个步骤中,有这样一段SQL
select distinct(server) from user_record where type = 'GD0001'
user_record表中的数据大概有2000万条左右 , 字段type的值为GD0001的记录大概有500万,而这段SQL执行的结果大概有30多条。type字段上有索引,但是SQL语句的执行时间却要超过一分钟。
得到去重后server字段的值是导致页面访问缓慢的根本原因。
根据程序的要求, server字段的值需要实时求得,所以当初在设计程序的时候才会使用这段SQL去获得结果。数据量少的时候,不会出现问题,然而, 数据增长的速度超出当初的预期,于是就导致了性能问题的出现。
要解决这个问题不难,因为server字段值的范围相对是稳定的,可以想办法把值提取出来放到一个冗余的表里面,并且通过某种机制让这个新表的值与原表中server字段的值保持同步,查的时候查这个新表, 这样访问速度缓慢的问题也就迎刃而解了。
显然,使用这种方案解决问题需要不小的工作量。要使解决这个问题的成本最小化,最好的方法是优化这个查询,假如原本这个查询运行的时间是一分钟,那么能使运行这个查询的时间下降至一秒,问题也算解决。
这个目标看起来似乎难以实现,事实上却是可以做到的。
select distinct(server) from user_record where type = 'GD0001'
因为这段SQL语句的筛选条件type字段有索引,所以整个SQL语句的逻辑查询步骤大致如下
通过type索引筛选出符合要求记录的主键字段的标识
通过主键标识定位到表中记录的源数据
拿到字段的值进行distinct去重得到最终的结果。
上面的三个步骤中,最消耗性能的是第二步。因为索引和表的实际数据其实是分开放置的,大概的样子如下面这个图。图中长的最大的那个其实就是数据表,表中所有的数据都在上面,只是看起来不像一张“表”而已。
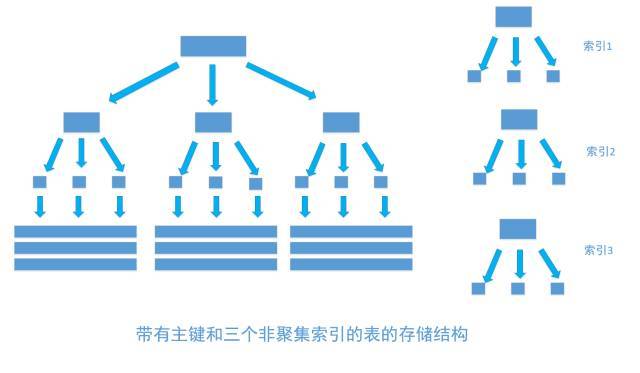
第二步是通过索引筛选出符合条件的记录的主键标识定位到实际数据,过程大概如下面这张图
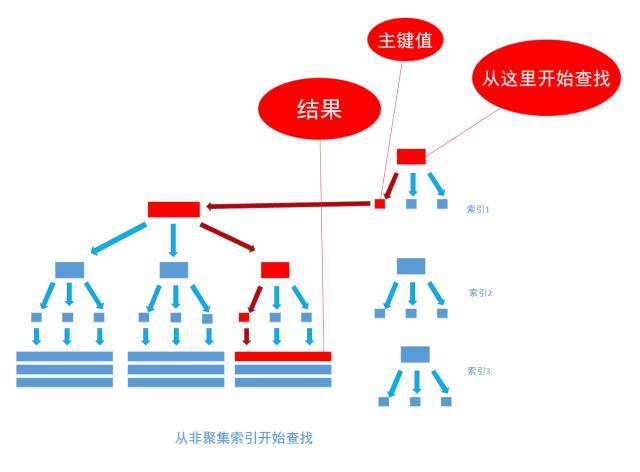
想象一下, 要优化的那段SQL,而type值为GD0001记录有500万条, 就算MySQL不会蠢到去查500万次才能得到结果,但也肯定不是轻轻松松就能完成的。 如果能优化掉这一步,整个查询的开销也就下去了。
select distinct(server) from user_record where type = 'GD0001'
对于这段SQL,我们的目标是并不是得到所有字段的值,仅仅server字段的值就足够了。
假如我们把server字段的值放在type字段的索引里,那么在第一步查索引的时候就能得到第二步的结果。执行过程如下图
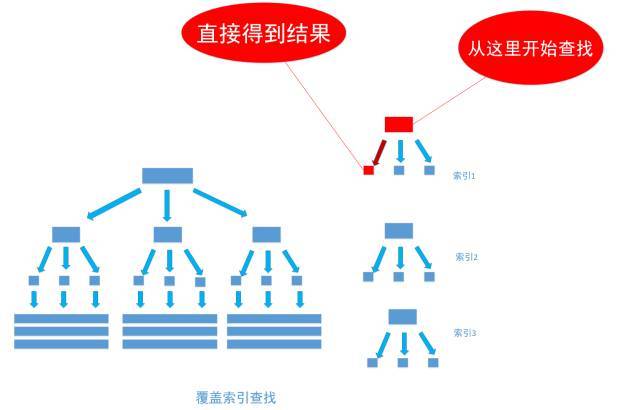
在关系数据库中,有一种索引称为覆盖索引,就是为了满足这种优化需求而设计的。
针对这段SQL语句优化的覆盖索引创建语句如下
create index index_type_server on user_record(type, server)
这个索引创建语句会将type和server两个字段的值组织在一个索引里面, 因此当
select distinct(server) from user_record where type = 'GD0001'
所有的查询步骤在索引中就能完成,而不用再去源数据表里提取数据,也就是在没建立这个索引时进行查询的第二步被消除了,因此查询的性能极大幅度的得到了提升。
在没建立覆盖索引前,查询的时间需要一分钟以上,在建立索引后,查询的时间下降到几百毫秒的级别。原本网页加载缓慢和偶尔报HTTP 502错误失去响应的问题也得到了解决。
让SQL语句合理的利用索引快速的得到查询结果是一门学问,值得深究。 合理利用索引,能让对程序性能的优化从代码层面转移到数据库层面, 让问题由最适合解决的工具和手段去解决,物尽其用,如此不但能减少代码复杂度,还能提高解决问题的效率。这是一个程序员必须要具备的一种技能。
延伸阅读:http://www.cnblogs.com/aspwebchh/p/6652855.html
原文链接:https://www.chhblog.com/article_view?id=385
7
4
4
2
2

